Comment bâtir votre plateforme de suivi web à partir de zéro
Le suivi web fait référence à la pratique de collecte et d'analyse de données sur le comportement des visiteurs d'un site Web. Cela se fait généralement grâce à l'utilisation de technologies de suivi telles que les cookies, les balises Web et le code JavaScript.
Lorsqu'un utilisateur visite un site, les technologies de suivi peuvent être utilisées pour collecter des informations sur son comportement: les pages qu'il visite, les liens sur lesquels il clique, le temps qu'il passe sur chaque publication et les produits qu'il achète.
En général, les plateformes intègrent Google Analytics dans leur site web pour avoir les informations de comportement de leurs visiteurs. Mais dans le cas où vous avez des besoins plus spécialisés, vous devrez considérer créer votre propre infrastructure de suivi.
C'est ce que nous avons fait pour la plateforme Wutsi:
1. Pour offrir à chaque auteur les informations sur le comportement de leur lecteurs afin de leur permettant de comprendre:
- Combien de visite il y a sur leur publications?
- D'où proviennent ces visiteurs?
- Combien de temps les visiteurs passent-ils à lire leurs publications?
- etc.
2. Pour rémunérer les auteurs du Wutsi Partner Program en fonction du temps de lecture mensuel sur leur publications
Dans cette article, nous allons présenter l'architecture de la plateforme de suivi de Wutsi.
Qu'est ce que Wutsi?
Wutsi est une plateforme de blogging qui permet aux auteurs de monétiser leur contenu:
- via le Wutsi Partner Program qui permet aux auteurs de recevoir des revenus en fonction du traffic dans leur blog.
- via le Wutsi Store qui permet aux auteurs de vendre leur e-books.
- en recevant des dons de leurs lecteurs.
La plateforme analytique de Wutsi
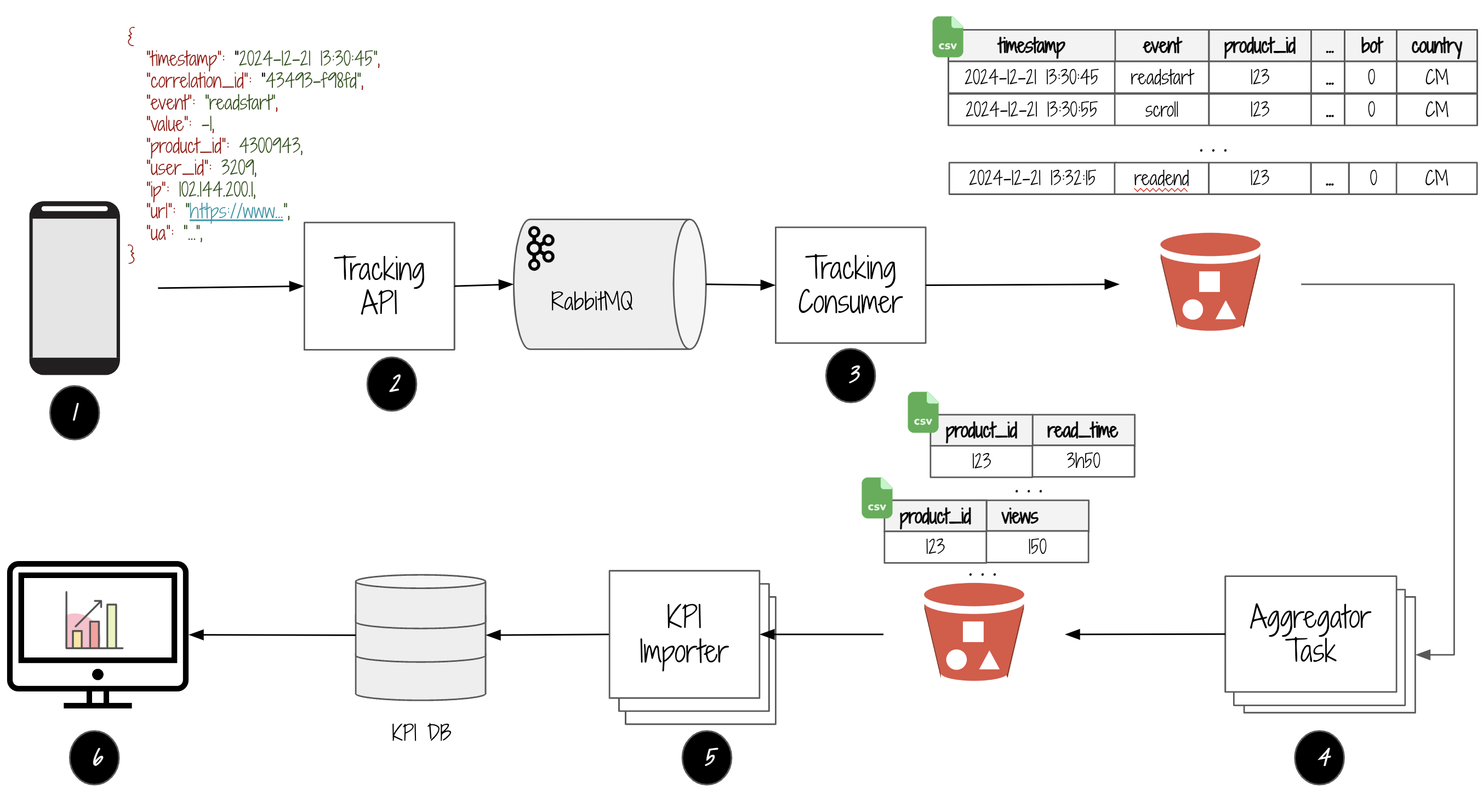
1. L'aquisition des interactions
La première étape consiste à intercepter toutes les interactions des usagers avec l'app et de les convertir en événements:
- Lorsque un lecteur ouvre une publication, l'événement
readstartest généré pour indiquer que la lecture d'une publication démarre. - Lorsque un lecteur défile son écran (vers le haut ou le bas), l'événement
scrollest généré. - Lorsque un lecteur aime une publication, l'événement
likeest généré. - Lorsque un lecteur ferme la publication, l'événement
readendest généré pour indiquer que la lecture d'une publication est terminée.
L'aquisition des interactions des usagers se fait en gérant les événements Javascript du document HTML
<script>
document.addEventListener("DOMContentLoaded", function () {
track('readstart');
window.addEventListener('beforeunload', function () {
track('readend');
});
window.addEventListener('scroll', function () {
const percent = compute_scroll_percent();
track('scroll', percent);
});
...
});
function track(event, value){
...
}
</script>
2. L'expédition des événements
La prochaine étape est d'envoyer les événements d' interactions dans un message JSON à l'API de suivi (Tracking API) qui le publie dans RabbitMQ.
Le message JSON contient les informations suivantes:
- Le
correlation_id, qui est un identificateur unique qui associe toutes les interactions associées à une visite sur une publication - La date et heure quand l'événement a été généré
- L'événement. Exemple:
readstart,readend,scrolletc. - La valeur associée a l'événement.
- L'identification du produit
- L'identification de l'usager
- L'adresse IP de l'usager
- L'URL de la page où l'événement a été généré
- Les informations du navigateur, provenant de l'entête HTTP
User-Agent.
3. Le stockage des messages
L'étape suivante est de stocker les messages dans Amazon S3:
1. Le Tracking Consumer reçoit les messages expédiés par le Tacking API via RabbitMQ
2. Il enrichit chaque message en ajoutant des informations additionnelles:
- Le pays de l'usager à partir de son adresse IP.
- La provenance du trafic: réseau social? des engins de recherche? emails?
- etc.
3. Les messages sont groupés en lot de 1000 et stockés en CSV dans S3. Les fichiers sont stockés dans une structure de répertoires ayant le format /track/<ANNEE>/<MOIS>/<JOUR>/, pour organiser les fichiers par chaque jour de l'année.
4. Le calcul des métriques
L'étape suivante est de traiter les fichiers CSV des messages toute les 2 heures et de générer des métriques mensuelles telles que:
- Le nombre de vues par publication
- Le temps total de lecture par publication
- Le nombre de vues par publication et par source de trafic (Réseau sociaux vs Email vs SEO etc.)
- Le nombre de lecteurs par publication
- Le nombre de vues par email par publication
- etc.
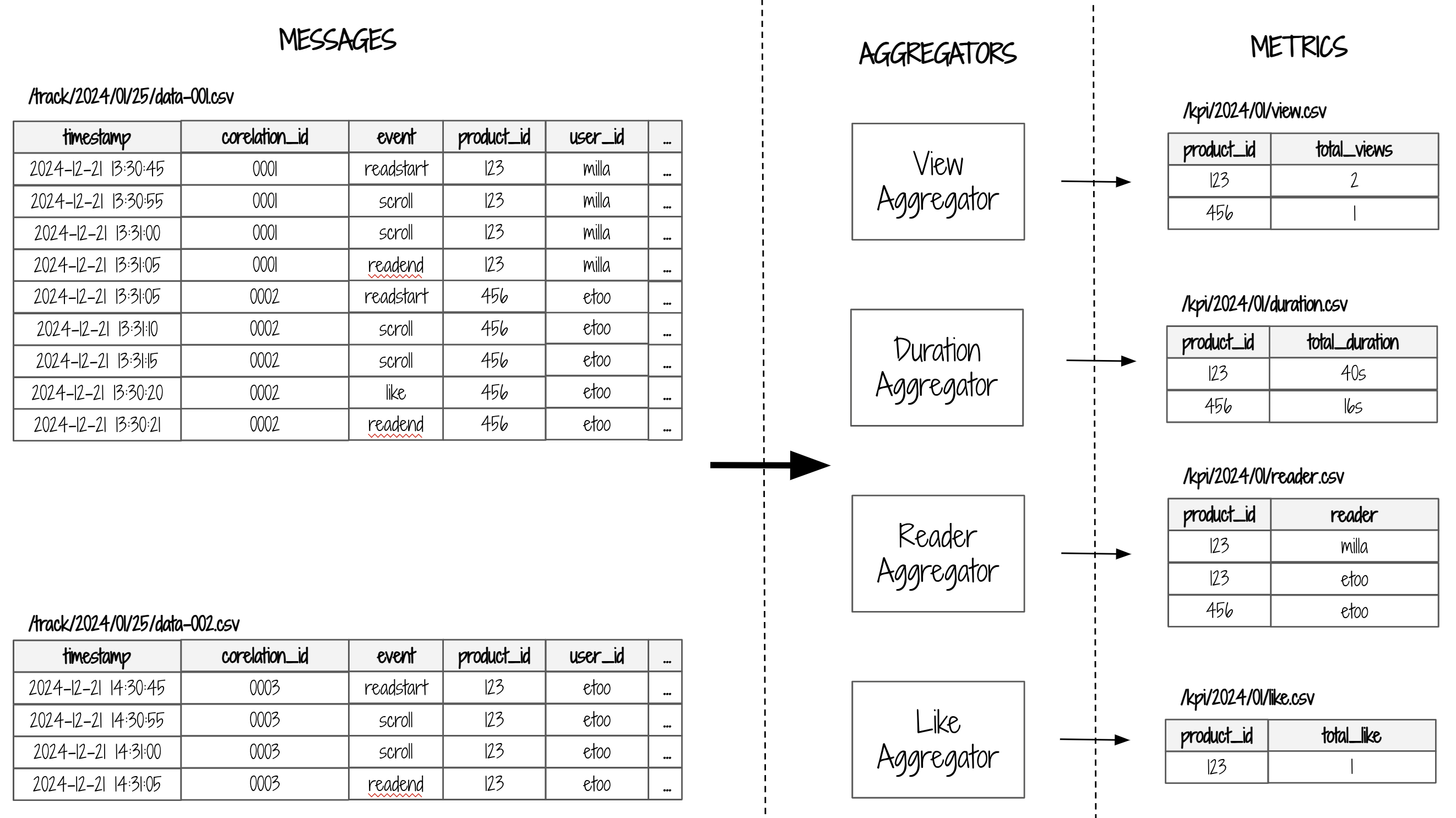
Chaque métrique est associée à un AggregatorTask dont le rôle est d'analyser tous les fichiers CSV du mois en cours et calculer les métriques, et les stocker dans un répertoire S3 ayant le format /kpi/<ANNEE>/MOIS/ afin d'organiser les métriques par mois.
5. L'importation des métriques
L'étape suivante est d'importer toutes les 3 heures les métriques dans une base de données relationnelle (MySQL).
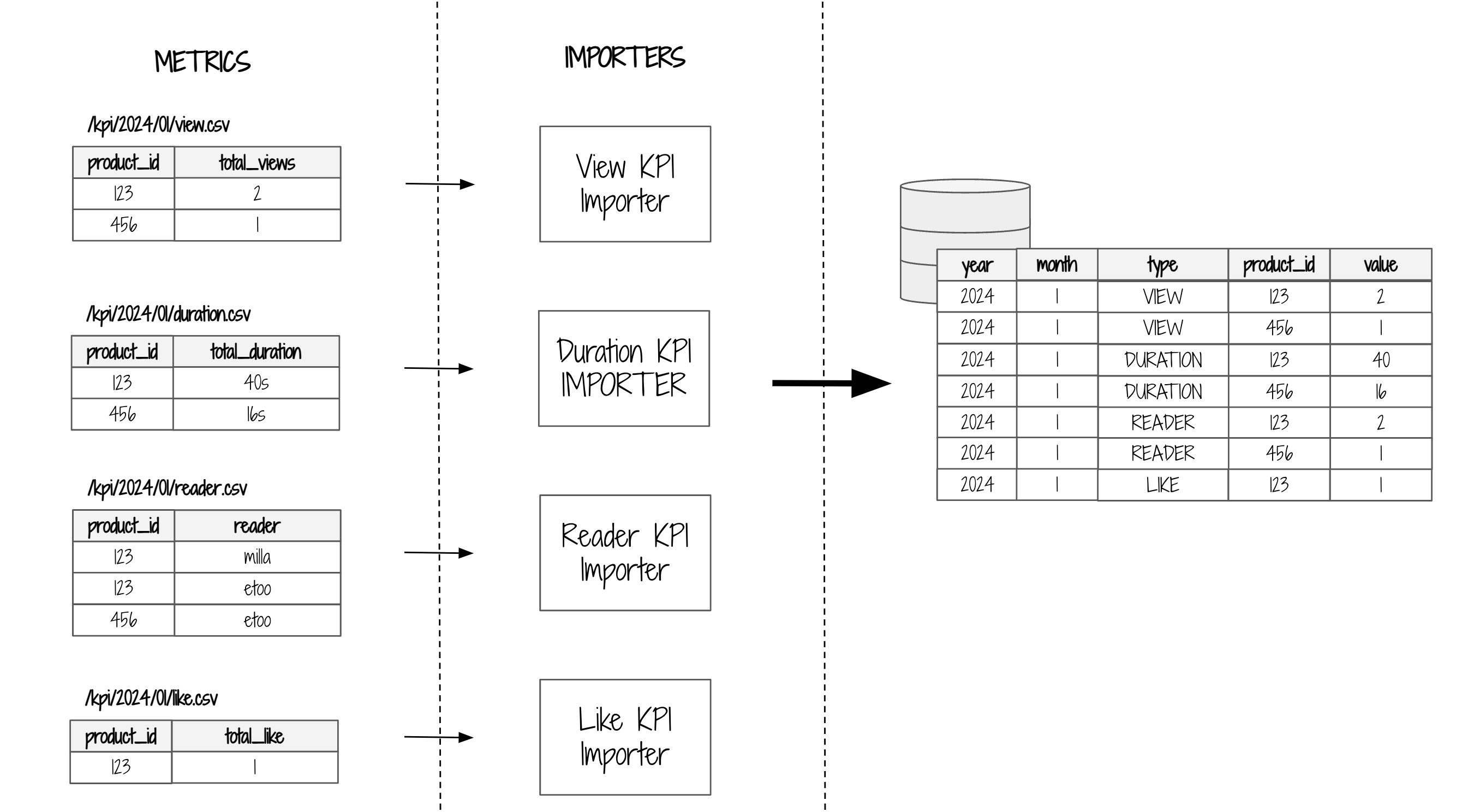
6. La visualization des métriques
Au bout de la chaîne, il y a une page web disponible à chaque auteur, qui lui permet de visualiser toutes les métriques de ses publications.
Les avantages de l'architecture
Tolérant aux pannes
Un système est tolérant aux pannes lorsqu'il continue son fonctionnement normal malgré la présence de pannes système ou matérielles.
Si le Tracking API est en panne et qu'on ne reçoit plus les messages d'interactions des clients:
- Les
Aggregator Taskcontinuent à produire les métriques mensuelles - Les
KPI Importercontinuent à importer les métriques en base de données. - Les auteurs continuent à visualiser leurs métriques
Le fait de faire concevoir le système en modules découplés qui roulent de façon indépendantes tout en s'échangeant les données (via RabbitMQ ou S3) rend le système tolérant aux pannes, car l'état d'un module n'a aucune incidence sur les autres.
Extensible
Un système est extensible lorsqu'il peut être amélioré ou étendu sans modifier de manière significative l'architecture de base.
L'amélioration de la plateforme c'est fait au fil des années en supportant de nouvelles métriques.
- Il faut juste ajouter de nouveau
Aggregator TasketKPI Importerpour traiter ou produire les fichier CSV - Au besoin, on peux supporter de nouvelles informations dans les messages en ajoutant de nouvelles colonnes dans le fichier CSV des messages. Ceci se fait sans mettre en péril nos structures de données.
Simple
Un système est simple lorsqu'il est dépourvu de complexité superflu. Les systèmes complexes ont les caractéristiques suivantes:
- Ils sont difficile à modifier pour introduire de nouvelle fonctionnalités
- Ils ont une courbe d’apprentissage abrupte, ce qui rend difficile d'intégrer des nouveaux membres de l'équipe.
Pour ce système, on a fait des choix techniques favorisant prioritairement la simplicité:
- On a découpé le système en modules indépendants, chacun d'eux effectuant uniquement une seule tâche.
- On a utilisé S3+CSV pour le stockage des messages (au lieu de JSON+MongoDB ou Firebase) parce que S3 offre la simplicité d'un système de fichiers; et les fichiers CSV peuvent être facilement traités ou téléchargés localement pour les besoins de tests.
- Les métriques sont stockées dans MySQL, qui est un base de données puissante ayant une large communauté d'utilisateurs.
- Le code requis pour implémenter un
Aggregator TaskouKPI Importerest tres relativement simple car ils effectuent généralement des opérations de calculs de base.
Replay
Le replay est la faculté de régénérer les métriques en ré-exécutant des Aggregator Task à travers tous les messages CVS stockés dans S3.
Si par exemple on a un bogue dans un Aggregator Task qui a produit des métriques invalides sur plusieurs périodes, on fixe le bogue et ensuite on fait un replay sur tous les messages CSV dans S3 pour corriger les métriques.
Lorsqu'on intègre une nouvelle métrique dans le système, on ajoute un nouveau Aggregator Task et on le replay sur tous les CVS, et toutes les métriques sont générés depuis le jour #1.
La plateforme de suivi a été conçue et développée en 2020, et fonctionne depuis lors et n'a subi aucune refonte majeure. Au fil des années, plusieurs métriques ont été ajoutées, l'infrastructure à été mise a l'échelle afin de s'adapter au trafic du site qui a augmenté de 50,000 messages/mois à plus de 7,000,000 messages/mois en 2024.
Si vous avez aimé l'article, montrez votre soutien avec un ❤️ et abonnez-vous à mon blog! Votre engagement m’inspire!
